大主子表关联的性能优化方法
主子表是数据库最常见的关联关系之一,最典型的包括合同和合同条款、订单和订单明细、保险保单和保单明细、银行账户和账户流水、电商用户和订单、电信账户和计费清单或流量详单。当主子表的数据量较大时,关联计算的性能将急剧降低,在增加服务器负载的同时严重影响用户体验。作为面向过程的结构化数据计算语言,集算器 SPL 可通过有序归并的方法,显著提升大主子表关联计算的性能。
1、原理解释
所谓主子表关联计算,就是针对主表的每条记录,按关联字段找到子表中对应的一批记录。以订单(主表)和订单明细(子表)为例,两者以订单ID为关联字段。下图显示了关联计算过程中对主表中一条记录的处理情况,红色箭头代表没找到对应记录(不可关联),绿色箭头代表找到了对应记录(可关联):
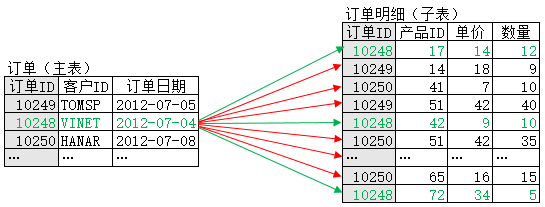
假设订单(主表)有m条记录,订单明细(子表)有n条记录,在不考虑优化算法时,主表中每一条记录的关联都需要遍历子表,相应的时间复杂度为O(n)。而主表一共有m条记录,所以整个计算的复杂度就是O(m*n),显然过高。虽然数据库一般会采用hash方案来优化,但在数据量较大或较多表关联时,仍然会面临时难以并行、使用外存缓存数据的问题,性能依旧会急剧下降。
而对于集算器来说,针对大主子表关联算法,可以通过两步来实现显著优化:数据有序化、归并关联。
数据有序化
对主表和子表,首先分别按照关联字段排序,形成有序数据。
归并关联
首先在主表和子表上分别用指针指向第一条记录,然后开始比对,对于主表的第一条记录,如果子表遇到匹配的记录,则表示可以关联,记录后子表指针前移;如果遇到不匹配的记录,表示主表第一条记录的关联计算完成,此时子表指针不动,主表指针下移一位,指向第二条记录。以此类推……
优化后,单条记录的关联计算可用下图示意:
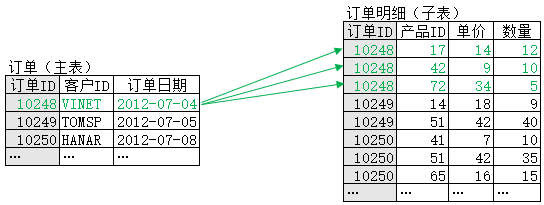
可以看到,经过优化,主表中单条记录的关联只需比对部分数据,不再需要遍历子表。事实上,对主表所有记录的关联,才会遍历一次子表,也就是复杂度为O(n)。再加上主表本身会遍历一次,因此整个计算的复杂度就是O(m+n)。
这样,经过集算器优化后,算法的时间复杂度变为线性,而且不再需要生成落地的中间数据,性能自然得到大幅提升。
当然,需要注意的是,有序化本身也会耗费时间,因此这种优化方法不适合只做一次的关联算法。但在实际业务中,关联算法通常会反复执行,这时有序化的开销就是一次性的,完全可以忽略不计。
2、具体实现
下面还是以订单和订单明细为例,说明集算器优化大主子表关联的方法。
首先进行数据有序化(注意,这是一次性动作)。集算器脚本“数据有序化.dfx”如下:
| A | B | |
| 1 | =connect(“orcl”) | |
| 2 | =A1.cursor(“select 订单ID,客户ID,订购日期 from 订单 order by 订单ID”) | =A1.cursor(“select 订单ID, 产品ID,单价,数量 from 订单明细 order by 订单ID,产品ID”) |
| 3 | =file(“订单.ctx”).create(#订单ID,客户ID,订购日期) | =file(“订单明细.ctx”).create(#订单ID,#产品ID,单价,数量 ) |
| 4 | =A3.append(A2) | =B3.append(B2) |
| 5 | =A1.close() |
A1连接Oracle数据源,A5关闭数据源。集算器可连接大部分常用数据源,包括数据库、Excel、阿里云、SAP等等。
A2、B2:用SQL语句分别取订单和订单明细,并按关联字段排序。由于数据量较大,无法一次性读入内存,因此这里用到了游标函数cursor。
A3、B3:分别创建组表文件“订单.ctx”和“订单明细.ctx”,用于存储有序化之后的数据。这里需要指定字段名,其中带#号的字段是主键,。数据将按主键排序,且主键的值不可重复。
A4-B4:将游标追加写入组表文件。
其次,对于通常会反复执行的关联算法,可以用集算器脚本“归并关联.dfx”实现如下:
| A | B | |
| 1 | =file(“订单.ctx”).create().cursor(订单ID) | =file(“订单明细.ctx”).create().cursor(订单ID,数量) |
| 2 | =joinx(A1:主表,订单ID; B1:子表,订单ID) | |
| 3 | =A2.groups(;sum(子表.数量)) |
A1、B1:读入组表文件“订单.ctx”和“订单明细.ctx”。注意组表默认为列式存储,因此只需读入后续计算需要的字段,从而大幅降低I/O。
A2:对有序游标A1、B1进行归并关联,其中“主表”、“子表”是别名,方便后续引用,如果省略别名,后续可以通过默认别名_1、_2引用。注意,函数joinx默认进行内关联,可用选项@1指定左关联,或者@f指定全关联。如果有多个游标都要与A1关联,可用分号依次隔开。
A3:对关联结果进行后续计算,例如汇总产品数量。事实上后续计算可以支持任意算法,也不是本文的讨论范围了。
上面介绍了集算器SPL脚本的写法,而在实际执行时,还需要部署集算器的运行环境。有两种部署方式可供选择:内嵌部署和独立部署。
内嵌部署
内嵌部署时,集算器的用法类似内嵌数据库,应用系统使用集算器驱动(JDBC)执行同一个JVM下的集算器脚本。
下面是Java调用“归并关联.dfx”的代码
| 1. com.esproc.jdbc.InternalConnection con=null;2. try {3. Class.forName(“com.esproc.jdbc.InternalDriver”);4. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection(“jdbc:esproc:local://”);5. ResultSet rs = con.executeQuery(“call 归并关联()”);6. } catch (SQLException e){7. out.println(e);8. }finally{9. if (con!=null) con.close();10. } |
在上述JAVA代码中,集算器脚本以文件的形式保存,调用语法类似存储过程。而如果脚本很简单,也可以不保存脚本文件,直接书写表达式,调用语法类似SQL,这时第5行可以写成:
| ResultSet rs = con.executeQuery(“=joinx(file(\”订单.ctx\”).create().cursor(订单ID),订单ID; file(\”订单明细.ctx\”).create().cursor(订单ID,数量),订单ID).groups(;sum(_2.数量))”); |
这篇文章详细介绍了JAVA调用集算器的过程:http://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html
除了使用Java代码,也可以通过报表访问集算器,这时按照访问一般数据库的方法即可,具体可参考《让Birt报表脚本数据源变得既简单又强大》。
对于脚本“数据有序化.dfx”,可以用同样的方法执行。不过这个脚本通常只执行一次,所以也可以直接在命令行中执行,windows用法如下:
| D:\raqsoft64\esProc\bin>esprocx 数据有序化.dfx |
Linux下用法类似,可以参考http://doc.raqsoft.com.cn/esproc/tutorial/minglinghang.html
独立部署
独立部署时,集算器的用法类似远程数据库,应用系统可以使用集算器驱动(JDBC或ODBC驱动)访问集算服务器。这种情况下,应用系统和集算器服务器通常部署在不同的机器上。
例如集算服务器的IP地址为192.168.0.2,端口号为8281,那么JAVA应用系统可以通过如下代码访问:
| st = con.createStatement();st.executeQuery(“=callx(\”归并关联.dfx\”;[\”192.168.0.2:8281\”])”); |
关于集算服务器的部署和使用,详细内容可参考http://doc.raqsoft.com.cn/esproc/tutorial/fuwuqi.html
关于JDBC和ODBC驱动的部署方法,可分别参考
http://doc.raqsoft.com.cn/esproc/tutorial/odbcbushu.html
3、多线程优化
前面介绍了基本的优化思路和实现方法,也就是针对数据本身的优化。而现实中服务器都是多核心CPU,因此可以进一步对上述算法进行多线程优化。
多线程优化的原理,是将主表和子表各分为N段,使用N个线程同时进行关联计算。
原理虽简单,但真正实现的时候,就会发现很多难题:
分段效率
想把数据分为N段,就要先找到每一段的起始行号,如果用遍历的笨办法数行号,显然会白白消耗大量的I/O资源。
数据跨段
理论上,关联字段值相同的子表记录,应该分到同一段。如果对子表随意分段,很可能形成跨段的数据。
分段对齐
更进一步,理论上,子表的第i段数据,应该与主表的第i段数据对齐,也就是主子表关联字段值的范围应该一致。如果两者各自独立分段,则可能导致分段数据难以对齐。
二次计算
如果后续计算不涉及聚合,例如只是过滤,那么只需将N个线程的计算结果直接合并。但如果后续计算涉及聚合,比如sum或分组汇总,那就要单独再进行二次计算聚合。
好在集算器已经充分解决了上述难题,分段时不会耗费IO资源、关联字段值相同的记录会分在同一段、子表和主表会保持对齐、各种二次计算无需单独实现。
具体来说,首先,数据有序化脚本需要做如下修改(红色字体为修改部分):
| A | B | |
| 1 | =connect(“orcl”) | |
| 2 | =A1.cursor(“select 订单ID,客户ID,订购日期 from 订单 order by 订单ID”) | =A1.cursor(“select 订单ID, 产品ID,单价,数量 from 订单明细 order by 订单ID,产品ID”) |
| 3 | =file(“订单多线程.ctx”).create(#订单ID,客户ID,订购日期) | =file(“订单明细多线程.ctx”).create(#订单ID,#产品ID,单价,数量 ;#订单ID ) |
| 4 | =A3.append(A2) | =B3.append(B2) |
| 5 | =A1.close() |
B3:生成“订单明细多线程.ctx”时,数据按“#订单ID”分段。这将保证订单ID相同的记录,将来会分到同一段。
归并关联的脚本需修改如下:
| A | B | |
| 1 | =file(“订单多线程.ctx”).create().cursor@m(订单ID) | =file(“订单明细多线程.ctx”).create().cursor@m(订单ID,数量;;A1) |
| 2 | =joinx(A1:主表,订单ID; B1:子表,订单ID) | |
| 3 | =A2.groups(;sum(子表.数量)) |
A1:@m表示对数据分段,形成多线程游标(也叫多路并行游标)。其中线程数量是默认值,由系统参数“最大并行数”决定,也可手工修改。例如希望生成4线程游标,A1应写成:
| =file(“订单多线程.ctx”).create().cursor@m(订单ID ;;4) |
B1:同样生成多线程游标,并与A1的多线程游标对齐。
A2-A3:归并关联,再执行后续算法。这两步写法上没变化,但底层会自动进行多线程合并和二次计算,从而降低了程序员的编程难度。
4、结构优化
在前面算法的基础上,还可以进一步提升计算性能,那就是以层次结构存储数据,直接记录关联关系。
具体来说,先用“结构优化有序化.dfx”生成组表文件:
| A | B | |
| 1 | =connect(“orcl”) | |
| 2 | =A1.cursor(“select 订单ID,客户ID,订购日期 from 订单 order by 订单ID”) | =A1.cursor(“select 订单ID, 产品ID,单价,数量 from 订单明细 order by 订单ID,产品ID”) |
| 3 | =file(“多层订单.ctx”).create(#订单ID,客户ID,订购日期) | |
| 4 | =A3.append(A2) | =A3.attach(订单明细,#产品ID,单价,数量) |
| 5 | =B4.append(B2) | |
| 6 | =A1.close() |
B4:在主表的基础上附加子表,命名为订单明细。与主表不同的是,子表默认继承了主表的主键,因此可以省略订单ID,只需要写另一个主键产品ID。这样,2个表写在了一个组表文件中,从而才能形成层次结构。
B5:向子表写入数据。
此时,组表“多层订单.ctx”将按层次结构存储,逻辑示意图如下:
| #订单ID | #产品ID | 单价 | 数量 | 客户ID | 订单日期 |
| 10248 | VINET | 2012-07-04 | |||
| 17 | 14 | 12 | |||
| 42 | 9 | 10 | |||
| 72 | 34 | 5 | |||
| 10249 | TOMSP | 2012-07-05 | |||
| 14 | 18 | 9 | |||
| 51 | 42 | 40 | |||
| 10250 | HANAR | 2012-07-08 | |||
| 41 | 7 | 10 | |||
| 51 | 42 | 35 | |||
| 65 | 16 | 15 | |||
| … | … | … | |||
| … | … | … |
可以看到,每条主表记录与对应的子表记录,在逻辑上已经紧密相关,无需额外关联,这样便可大幅提高关联算法的性能。
进行关联计算时,使用以下脚本“结构优化归并关联.dfx”:
| A | B | |
| 1 | =file(“多层订单.ctx”).create() | =A1.attach(订单明细) |
| 2 | =A1.cursor@m(订单ID) | =B1.cursor@m(订单ID,产品ID) |
| 3 | =joinx(A2:主表,订单ID; B2:子表,订单ID) | |
| 4 | =A3.groups(;sum(子表.数量)) |
A1、B1:打开主表,以及附加在主表上的子表。
A2、B2:以多线程方式分别读取主表和子表。需要注意的是,多层组表里的实表之间天然具备相关性,因此无需特意指定子表和主表的分段关系,代码比之前更清晰简单。
A3,A4:归并关联并执行后续算法,这两步没变化。
5、数据更新
前面的优化方式都基于库表全量导出为组表文件的情况,但实际业务中数据库表总会发生变化,因此需要考虑数据更新的问题,也就是要将变化的数据定时更新到组表文件中。
显然,更新数据应选择在无人查询组表文件时进行,一般都是半夜或凌晨。而更新的频率,则需要按照数据实时性要求来设定,例如每天一次或每周一次。至于更新的方式,需要按照数据的变化规律来考虑,最常见的是数据追加,有时也会遇到增删改。
下面先看数据追加:
订单和订单明细每天都会产生新记录,假设需要在每天凌晨2点将昨天新增的记录追加到组表文件中。下图显示了2018/11/23新增记录的情况,注意,有些订单(订单ID:20001)并没有对应的订单明细:
| 订单表 | 订单明细表 |
| 订单ID 客户ID 订单日期 19999 APK 2018/11/2220000 APK 2018/11/2320001 APJ 2018/11/2320002 APL 2018/11/2320003 APP 2018/11/24 | 订单ID 产品ID 单价 数量 19999 17 57.1 1519999 16 204.5 1620000 13 64.2 820000 14 640.2 220002 16 15.2 420003 19 245.2 5 |
把主子表追加到组表文件中的脚本 “追加组文件.dfx”如下:
| A | B | |
| 2 | =begin=datetime(elapse(date(now()),-1)) | =end=elapse(begin,1) |
| 3 | =connect(“orcl”) | |
| 4 | =A3.query@x(“select 订单.订单ID 主订单ID,订单明细.订单ID 子订单ID,产品ID,单价,数量,客户ID,订购日期 from 订单 left join 订单明细 on 订单.订单ID=订单明细.订单ID where 订购日期>? and 订购日期<=? order by 订单ID,产品ID”,begin,end) | |
| 5 | =A4.groups(主订单ID:订单ID,客户ID,订购日期) | =A4.select(子订单ID).new(子订单ID:订单ID,产品ID,单价,数量) |
| 6 | =file(“多层订单.ctx”).create() | |
| 7 | =A6.append(A5.cursor()) | =A6.attach(订单明细) |
| 8 | =B7.append(B5.cursor()) |
A2、B2:计算昨天的起止时间,以便查询新增数据。函数now获取当前时间点,理论上应该是2018-11-24 02:00:00。A2是昨天的起始时间点,即2018-11-22 00:00:00。B2是终止时间点,即2018-11-23 00:00:00。之所以在集算器中计算起止时间,主要是为了增加可读性和移植性。实际上也可以在SQL中计算。
A4:取出新增的主表和子表记录。这里用一句SQL取两张表的数据,主要是为了提高效率。由于有些订单并没有对应的订单明细,因此用订单左关联订单明细,且将对应不上的订单明细置空。计算结果如下:
| 主订单 ID | 子订单 ID | 产品 ID | 单价 | 数量 | 客户 ID | 订购日期 |
| 20000 | 20000 | 13 | 64.2 | 8 | APK | 2018/11/23 |
| 20000 | 20000 | 14 | 640.2 | 2 | APK | 2018/11/23 |
| 20001 | APJ | 2018/11/23 | ||||
| 20002 | 20002 | 16 | 15.2 | 4 | APL | 2018/11/23 |
A5、B5:拆出新增的主子表记录,结果示例如下:
| 订单ID 客户ID 订单日期 20000 APK 2018/11/2320001 APJ 2018/11/2320002 APL 2018/11/23 | 订单ID 产品ID 单价 数量 20000 13 64.2 820000 14 640.2 220002 16 15.2 4 |
A6-B8:将主表和子表追加到组表文件中。
脚本写完之后,还需要在每天的02:00:00定时执行,这可以使用操作系统内置的任务调度。
在Windows下,建立如下的bat批处理文件,:
| “D:\raqsoft64\esProc\bin\esprocx.exe” 追加组文件.dfx |
再使用windows内置的”计划任务”,定时执行批处理文件即可。
在linux下,建立如下的sh批处理文件,:
| /raqsoft/esProc/bin/esprocx.sh synclastday.dfx |
再使用crontab命令,定时执行批处理文件即可。
当然也可使用图形化工具定时执行脚本,比如Quartz。
需要注意的是,大多数情况下,能够选择无人使用组表文件的时候进行追加,但有些业务中组表文件全天都要使用,而有些项目对容错要求更高,要求追加失败时再次追加,这类项目就需要更加细致的追加方法,详情可参考《基于文件系统实现可追加的数据集市》。
除了追加这种主要的更新方式,业务中也会遇到增删改都存在的情况。
在这种情况下,就需要知道哪些是删除的记录,哪些是修改或新增的记录。如果条件允许,可以在原表中新加“标记”字段,并将维护状态记录在该字段中。如果不方便修改原表,则应当创建对应的“维护日志表”。例如下面两张表,分别是订单和订单明细的维护日志。
| 订单维护表 | 订单明细维护表 |
| 订单ID 客户ID 订购日期 标记 11108 OKBJ1 2012/11/23 删除 11107 VINET 2018/11/26 修改 30000 TOMSP 2018/11/26 新增 | 订单ID 产品ID 单价 数量 标记 1110817 10 0.1 10 删除 1110819 10 0.1 10 删除 1110717 20 0.1 20 修改 1110718 30 0.1 30 新增 3000020 40 0.1 40 新增 3000021 50 0.1 50 新增 |
根据维护日志更新组表文件,可使用下面的脚本:
| A | B | |
| 1 | =connect(“orcl”) | |
| 2 | =订单删除=A1.query(“select * from 订单维护where 标记= ‘删除’ “) | =明细删除= A1.query(“select * from 订单明细维护where标记= ‘删除’ “) |
| 3 | =订单修改新增= A1.query(“select * from 订单维护where 标记= ‘修改’ or标记= ‘新增’ “) | =明细新增修改= A1.query(“select * from 订单明细维护where标记= ‘修改’ or标记= ‘新增’ “) |
| 4 | =file(“多层订单.ctx”).create() | =A4.attach(订单明细) |
| 5 | =A4.delete(订单删除) | =B4.delete(订单删除) |
| 6 | =A4.update(订单修改新增) | =B4.update(订单修改新增) |
| 7 | =A1.execute(“delete * from 订单维护”) | =A1.execute(“delete * from 订单明细维护”) |
| 8 | =A1.close() |
A2、B2:从数据库查出应删除的记录
A3、B3:从数据查出应修改和新增的记录
A5、B5:对组表进行删除操作。
A6、B6:从组表进行修改新增操作。
A7、B7:清空维护日志表,以便下次继续更新数据。
6、T+0实时计算
通过定时追加,能保证组表文件与昨天的数据同步,从而实现T+1计算,但有时需要进行实时大主表关联,即T+0计算。
对于T+0计算,需要将两种不同的数据源进行混合计算,由于SQL或SP的数据模型较为封闭,因此难以实现混合计算,而使用集算器就非常简单。
比如对组表文件定时追加后,数据库当天又产生了如下新数据:
| 订单 | 订单明细 |
| 订单ID 客户ID 订购日期 …20002 APL 2018/11/2340000 VINET 2018/11/2640001 TOMSP 2018/11/2640002 HANAR 2018/11/26 | 订单 ID 产品 ID 单价 数量 …20002 16 15.2 440000 11 500 540000 12 600 640002 13 700.2 740002 14 800.2 8 |
可使用如下脚本实现T+0实时计算:
| A | B | |
| 1 | =begin=datetime(date(now())) | |
| 2 | =connect(“orcl”) | |
| 3 | =A2.query@x(“select sum(数量) as 总数 from 订单,订单明细 where 订单.订单ID=订单明细.订单ID and 订购日期>=?”,begin) | |
| 4 | =file(“多层订单.ctx”).create() | =A4.attach(订单明细) |
| 5 | =A4.cursor@m(订单ID) | =B4.cursor@m(订单ID,数量) |
| 6 | =joinx(A5:主表,订单ID; B5:子表,订单ID) | |
| 7 | =A6.groups(;sum(子表.数量):总数) | |
| 8 | =(A3|A7).groups(;sum(总数):总数) |
A1:算出当天的起始时间点,即2018-11-26 00:00:00。
A3:针对数据库当天产生的新数据,进行关联计算。由于当天数据量较小,因此性能可以接受。
A4-A7:针对组表文件历史数据,进行高性能关联计算。
A8:合并当天和历史,并进行二次计算,以获得最终计算结果。其中符号|表示纵向合并,这是实现混合计算的关键。事实上,这种写法也表明集算器支持任意数据源之间的混合计算,比如Excel与elasticSearch之间。
关于T+0计算更多的细节,可参考相关文章《实时报表 T+0 的实现方案》
暂无留言我要留言 »
请 登陆 评论